

Meta je službeno lansirala Llama 2 jezični model koji donosi mnogo promjena u odnosu na original. Prvenstveno se to odnosi na licenciranje, koje je od sada dostupno za komercijalnu upotrebu. Ovisno o specifičnim potrebama, korisnici mogu birati modele u rangu od 7 do 70 milijardi parametara. Ako je vjerovati najavama iz Mete, svi modeli iz linije Llama 2 imaju bolje performanse od usporedivih modela konkurencije.
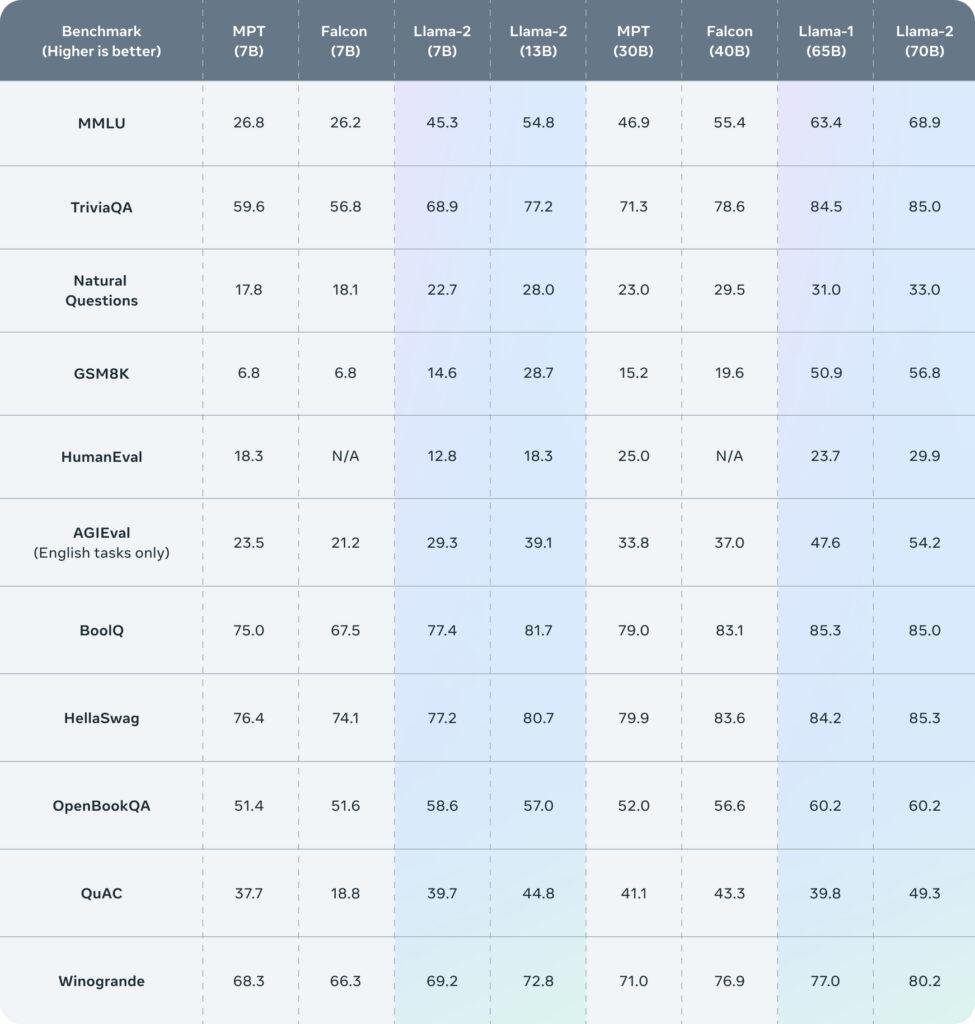
Lansiranje Llama 2 je svakako prekretnica u industriji jezičnih modela jer dolazi s nizom prednosti, od kojih treba istaknuti pred-trenirane modele za specifične namjene. Ovo bi trebalo značajno proširiti opseg djelovanja. Nadalje, Llama 2 dozvoljava odgovore u dužini 4096 tokena, što je više od svih trenutno dostupnih. Iako Llama 2 još nije na razini kvalitete ChatGPT 4 sustava, ima veliku prednost – naime, GPT nije open-source što znači da Llama 2 dozvoljava mnogo više slobode programerima i kompanijama za izgradnju aplikacija i sustava.
Prvi Llama model je pušten u promet u Veljači, ali nije dozvoljavao komercijalne licence. Kod je nekako završio na piratskim stranicama što je dovelo do masovne upotrebe i otvorilo vrata hakerima i drugim akterima da koriste AI modele za napade i hakiranje. Postavlja se pitanje kako zaštititi obične korisnike od napada potpomognutih AI-em, što će vrlo vjerojatno biti top tema sljedećih nekoliko godina.
Usprkos nedaćama, Meta je nastavila razvoj druge verzije modela ali uz veću transparentnost u pogledu treniranja, podataka i pristupa. Unatoč naporima, postoji velika doza skepticizma i otpora prema jezičnim modelima, ponajviše zbog korištenja nelicenciranih podataka, što je slučaj i s Metom. Nedavno smo pisali o otvorenom pismu autora, a sličnih inicijativa i tužbi ima svakim danom sve više.
Pa ipak, Llama 2 otvara put velikim jezičnim modelima otvorenog koda, što je velik odmak od trenutnog standarda koji su postavili OpenAI i Google, te je moguće očekivati još sličnih projekata u budućnosti.






{kind=link}